Handbuch / Anhang / Tabellen / Zeichentabelle

The Universal Coded Character Set ( UCS, Unicode) is a standard set of characters defined by the international standard ISO / IEC 10646, Information technology — Universal Coded Character Set (UCS) (plus amendments to that standard), which is the basis of many character encodings, improving as characters from previously unrepresented typing.
38 Convert Iso 8859 1 To Utf 8 Javascript Modern Javascript Blog

With UTF-8 you have increased flexibility over ISO 8859-1. The former can encode any character included in Unicode while the latter is limited to Western European languages.. ISO 8859-1 ("Latin1") doesn't include, for example, Greek, Hebrew, Arabic, Cyrillic, Chinese, Japanese and Korean, etc. Share. Improve this answer. Follow answered Jul.
C write textfile with encoding iso88591 is writing utf8 YouTube

More often you'll be seeing ISO-8859-1, which works for most Western European languages. The other versions of ISO-8859 work for Cyrillic, Arabic, Greek, or other specific scripts. However, if you want to display multiple scripts in the same document or on the same web page, UTF-8 allows for much better compatibility.
C Html Body Changes Its Charset From Utf 8 To Iso 8859 1 Stack Photos

Efficiency. UTF-8 requires 8, 16, 24 or 32 bits (one to four bytes) to encode a Unicode character, UTF-16 requires either 16 or 32 bits to encode a character, and UTF-32 always requires 32 bits to encode a character. The first 128 Unicode code points, U+0000 to U+007F, used for the C0 Controls and Basic Latin characters and which correspond one.
Cómo decodificar carácteres en formato UTF8 a ISO88591 Academia Rolosa

ISO/IEC 8859-1 encodes what it refers to as "Latin alphabet no. 1", consisting of 191 characters from the Latin script. This character-encoding scheme is used throughout the Americas, Western Europe, Oceania, and much of Africa. It is the basis for some popular 8-bit character sets and the first two blocks of characters in Unicode .
Curso FrontEnd U1·05 Codificación de caracteres UTF8 vs ISO88591 HTML YouTube
ISO-8859-1 vs UTF-8. When faced with the choice of character encoding, the choice is between flexibility and storage space and simplicity. If only ISO-8859-1 characters are to be used in a project (such as a website), then ISO-8859-1 does offer a slight benefit in terms of storage space, and therefore in the case of a web page, of download size.
Character Encoding Demystified Everything you Need to Know About ASCII, Unicode, UTF8 Borko
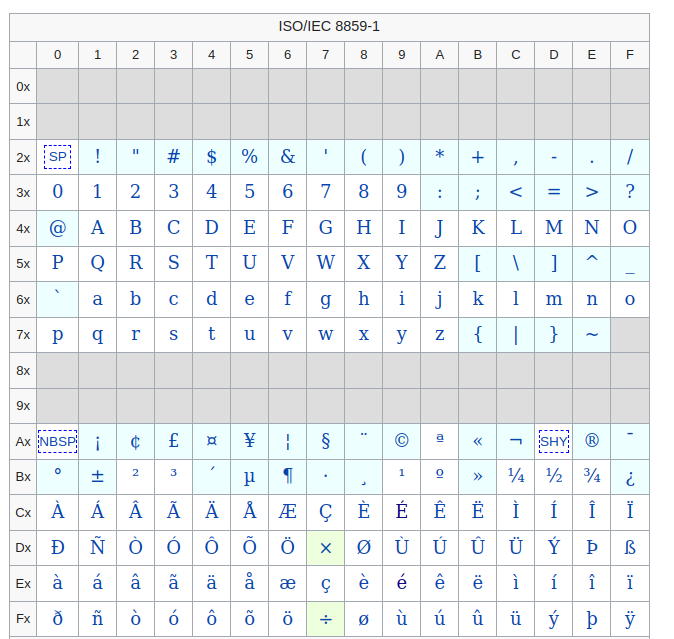
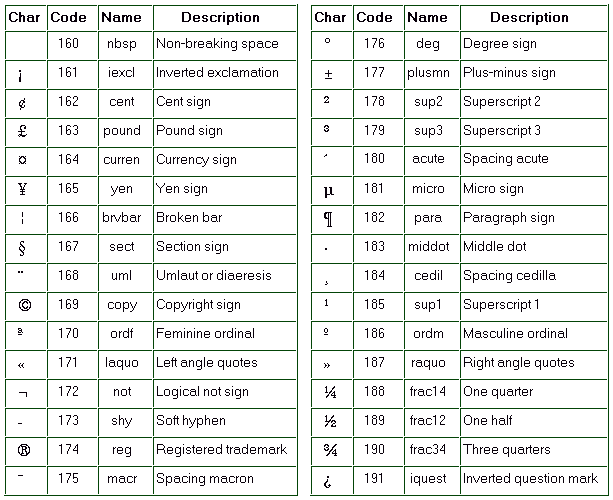
ISO-8859-1 is very similar to Windows-1252. In ISO-8859-1, the characters from 128 to 159 are not defined. In Windows-1252, the characters from 128 to 159 are used for some useful symbols. For a closer look, please study our Complete ANSI (Windows-1252) Reference. Since many web sites declare ISO-8859-1 and use the values from 128 to 159 as if.
Download free software Html Charset Iso 8859 1 Utf 8 fishingbackup
In 1987, the International Organization for Standardization (ISO) published a set of standards for eight-bit ASCII extensions, ISO 8859. The most popular of these was ISO 8859-1 (also called "ISO Latin 1") which contains characters sufficient for the most common Western European languages. Other standards in the 8859 group included ISO 8859-2 for Eastern European languages using the Latin.
(PDF) UTF8 & Latex Encodings of ISO8859 (Latin1) Character Set

Unicode is backwards compatible with ISO-8859-1 and ASCII. It is a 16 bit scheme and can represent quite a lot of characters and symbols. For English documents, using 16 bit for a character is a little wasteful. The 16 bit scheme requires twice the size needed for ISO-8859-1. To mitigate this issue a UCS transformation called UTF-8 is created.
ASCII TO UTF8 converter converts ASCII, ISO88591, Unicode, Western European Character sets etc.
UTF-8: Variable length encoding, 1-4 bytes per code point. ASCII values are encoded as ASCII using 1 byte. UTF-7: Usually used for mail encoding. Chances are if you think you need it and you're not doing mail, you're wrong. (That's just my experience of people posting in newsgroups etc - outside mail, it's really not widely used at all.)
charset=UTF8 ou ISO88591 importa para SEO? Réulison Silva

The "block" indicates that the font that is being used doesn't have a glyph available to display the character. ISO 8859-1 doesn't have those "smart" quotes. So what will happen is that the bytes representing those smart quotes end up as random other ISO-8859-1 characters, e.g. ôñquoted textÝâ. UTF-8 is safe.
CSS ISO88591 vs UTF8? YouTube

ISO 8859 is really only useful for European alphabets. To support most of the alphabets used in most Chinese, Japanese, Korean, Arabian, etc., alphabets, you have to use some completely different encoding.. This is more filling, but makes your data more resistant against ISO-Latin-1 vs UTF-8 encoding errors. This is what we do as our.
Converting Windows1252 and ISO88591 to UTF8 in C ParTech

To answer your second question -- U+0000 to U+00FF in UTF8 is identical to ISO 8859-1 (Latin-1). We use UTF-8 for encoding in all our websites and have not had any difficulties. Share. Improve this answer. Follow edited May 23, 2017 at 12:41. Community Bot. 1. answered.
CSS ISO88591 vs UTF8? YouTube

UTF-8 is a multibyte encoding that can represent any Unicode character. ISO 8859-1 is a single-byte encoding that can represent the first 256 Unicode characters. Both encode ASCII exactly the same way. If you want world domination, use UTF-8 all the way, because this covers every human character available at the world, including Asian, Cyrillic.
Function to convert ISO88591 to UTF8 (4 Solutions!!) YouTube

Documents must also not use CESU-8, UTF-7, BOCU-1, or SCSU encodings,. UTF-8, or failing that ISO-8859-8-i). The replacement encoding, listed in the Encoding specification, is not actually an encoding; it is a fallback that maps every octet to the Unicode code point U+FFFD REPLACEMENT CHARACTER. Obviously, it is not useful to transmit data.
Unix & Linux Batch change encoding ascii files from utf8 to iso88591 (3 Solutions!!) YouTube

Wikipedia explains both reasonably well: UTF-8 vs Latin-1 (ISO-8859-1). Former is a variable-length encoding, latter single-byte fixed length encoding. Latin-1 encodes just the first 256 code points of the Unicode character set, whereas UTF-8 can be used to encode all code points.
.